
模仿川普语气真假难分,康奈尔盲测15亿参数模型:从未如此逼真,最强编故事AI完全体来了
本文转载自微信公众号 “ 量子位 ”,作者:乾明 鱼羊 栗子 十三 本文观点不代表本方观点。
还记得那个编故事能以假乱真的AI模型吗?
它叫GPT-2,因为效果太好,OpenAI说不能放出全部——让坏人误用就不好了。
于是,它初出茅庐时先放出了124M版本的模型,然后是355M,再然后是774M。
被业内称为 “ 挤牙膏式开源 ” 。
然而没想到,经过9个月断断续续发布,OpenAI终于把15亿参数的完整模型,放了出来。
正所谓好饭不怕晚,官方版放出之后也引起了好多人围观。
有人说 “ 好人一生平安 ”。也有人给OpenAI点赞,说唯一安全的AI,就是面向所有人的AI,而不是少数人的AI。
不少人也感叹于15亿参数模型的效果,表示 “ 假论文 ” 的时代不远了。

但更多的人是想扒清楚:
这个当初 “ 吊炸天 ” 的AI模型,到底有没有那么玄乎?
实测15亿版本模型
先来看看我们上手测试的效果吧。
首先,我们问它对熬夜变傻有科学依据了怎么看,输入是这样的:
There’s scientific evidence that staying up late makes you stupid.
它竟然给出了一个Twitter体的回答,还顺便Q了一下川建国:
There’s scientific evidence that staying up late makes you stupid. So why is it okay for the president to be up late every night, and be tweeting?
https://t.co/0j5cFZ5sXS — The Daily Show (@TheDailyShow) January 6, 2017
熬夜变傻有科学依据了。那么,为什么总统每天晚上很晚才起床,还要发推呢?
https://t.co/0j5cFZ5sXS—TheDailyShow (@TheDailyShow) 2017年1月6日
Here’s where Trump got it right:
这就是特朗普认为这样做正确的地方:
If I had been a wiser man, I would have used the term “sad” to describe my feelings toward watching all of you go to sleep. Sad! — Donald J. Trump (@realDonaldTrump) January 6, 2017
如果我是个明智的人,我就会用 “ 难过 ” 这个词来形容我看着你们所有人入睡的感受。难过!
—唐纳德·特朗普(@realDonaldTrump) 2017年1月6日
甚至还有推文链接、具体的账号和时间。
吓得我们赶紧去查了查,还好链接是胡编的,根本打不开。但这些推文账号都存在。
如此效果,很让我们震惊,将这个感受输入进去:
The editors were shocked by the effect.
然后得到了这样的“ 胡编 ”生成结果:
A few years later, in the late 1990s, a book was published that offered evidence for the existence of a “gene for human intelligence.”
几年后,也就是20世纪90年代末,一本书出版了,为 “人类智力基因 ” 的存在提供了证据。
“ I’m just astonished that this is the case, ” said Robert Rosenthal, a psychologist at the University of California at San Diego who was one of the editors of the report.
“ 我只是对这种情况感到惊讶,” 加州大学圣地亚哥分校的心理学家、该报告的编辑之一罗伯特·罗森塔尔说。
Rosenthal called the notion that intelligence can be detected with DNA “ totally implausible.”
罗森塔尔称,智力可以通过 DNA 检测的说法 “ 完全不可信 ”
虽然真实性有待考证,但这个逻辑已经像模像样,而且有细节、有论证,不了解实情的人,可能真的会被忽悠过去。
模型更大,胡编的能力也更强了
OpenAI在博客里说,GPT-2的生成结果,有独立客观第三方的检验,令人信服:
团队在康奈尔大学的合作伙伴,对人类做了问卷调查,给GPT-2输出的文本打出可信分 (Credibility Score) ,各种大小的模型都参与了。
满分10分,大家给15亿参数模型的可信分是6.91。比7.74亿参数的模型 (6.72分) 和 3.55亿参数的模型 (6.07分) 都要高。
也就是说在人类眼里,15亿参数模型,比之前放出的那些模型,写出的文章更逼真了。
那么在AI眼里,会不会也是如此?
于是写个检测算法,识别哪些是GPT-2写的文章,哪些是人类写的文章,同样是一项重要的工作。
OpenAI做了一个检测模型,识别15亿模型生成的文本,准确率大约95%。但这还不代表AI生成的文本是安全的。
因为,团队又对检测算法做了更仔细的考察,跨数据集的那种。
比如,训练时用3.55亿参数模型的作品,测试时却要识别15亿参数模型的文章;训练针对15亿参数模型,测试时要识别3.55亿参数模型的作品等等。
结果如下:
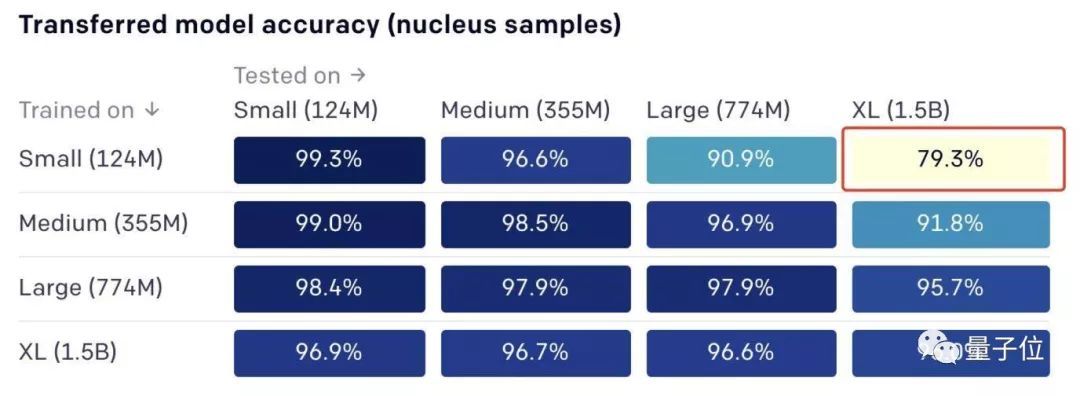
目前看来,用大模型的作品当训练集,可以轻松识别小模型的作品;但用小模型的作品当训练集,要识别大模型的作品,颇有些难度。
比如,用1.24亿参数模型的文章训练之后,再让算法识别15亿参数模型的作品,准确率只有79.3%。反过来,准确率有96.9%。
总体来看,15亿参数模型的作品,依然是最难识别的。
得出这样的结果,一方面看出15亿参数模型比从前的模型更强大。另一方面,也表示检测真伪的算法还有很长的路要走。
但也有人指出了这个模型存在的另外一些问题:
文本生成模型够大了,但我们需要的是可控的文本生成。
